
人工知能(Artificial Intelligence; AI)は、2010年頃から急速に発展を遂げてきました。特に、ChatGPTのような生成系AIは、まるで人間とやりとりするように質問に答えてくれ、世界中で注目を集めています。こちらが求める情報を驚くほど自然な言語で提示し、また、こちらが指示したテイストで画像を生成してくれます。このような複雑なやり取りを、生成系AIはいかにして実現しているのでしょうか。今回は、ChatGPTを例に、生成系AIが人間と “対話” する仕組みを紹介します。
【寺田 一貴・北海道大学CoSTEP/(協力)GPT-4】

自然言語とプログラミング言語
日本語や英語といった、私たちの日常生活で使う言語を自然言語といいます。自然言語は、使う人や使われる時代によって、また、使われるうちに、使い方(文法)や意味が変わっていきます。
一方で、従来のコンピューターが扱う言語をプログラミング言語といいます。プログラミング言語には厳密な文法や決まった解釈があり、自然言語が持っているような曖昧さはありません。

コンピューターが自然言語を処理するためには文脈の理解が必要だ
このようなプログラミング言語を扱うことを得意とするコンピューターが、私たちの扱う曖昧な自然言語を理解・解析・生成することを、自然言語処理(Natural Language Processing; NLP)といいます。コンピューターが曖昧な自然言語を扱うためには、私たちが無意識に行っている文脈の理解をする必要があります。しかし、コンピューターそのものは、文脈を理解することはできませんでした。
そこで、研究者は、まず、プログラミング言語を厳密に制御することで、コンピューターに文脈を理解させようとしました。しかし、厳密な文法を要するプログラミング言語で曖昧な自然言語の文脈を理解させるのは、根本的に困難なことでした。
この課題の克服に大きく貢献しているのが、膨大なデータを元に深層学習(ディープラーニング)した大規模言語モデル(Large Language Model; LLM)と呼ばれるモデル(処理の枠組み)です。膨大なのは元にするデータの数だけでなく、必要な計算量や、計算する要素(パラメーター)の数も、とされています1)。ディープラーニングの進化や、新しいグラフィックスプロセッサ(Graphics Processing Unit; GPU)の登場により、これほどまでに膨大な量のデータセットを元に様々なパラメーターを計算し、学習できるようになってきています。
大規模言語モデルはどのように自然言語を処理するか
大規模言語モデルでは、どのような自然言語処理が行われているのでしょうか。基本的な流れは、以下の通りです。この、「次のトークンの予測」という過程が、AIが人間とやり取りするときのポイントとなります。
- 入力された文字列をトークンと呼ばれる小さな要素(最小単位)に分割します。
- トークン同士のつながり(文脈)を数値として計算します。
- 学習したデータセットの特徴にどの程度トークンが一致しているか(特徴量)、数値として算出します。
- 特徴量を元に、次のトークンを予測します。
- 次のトークンの確率を算出します。
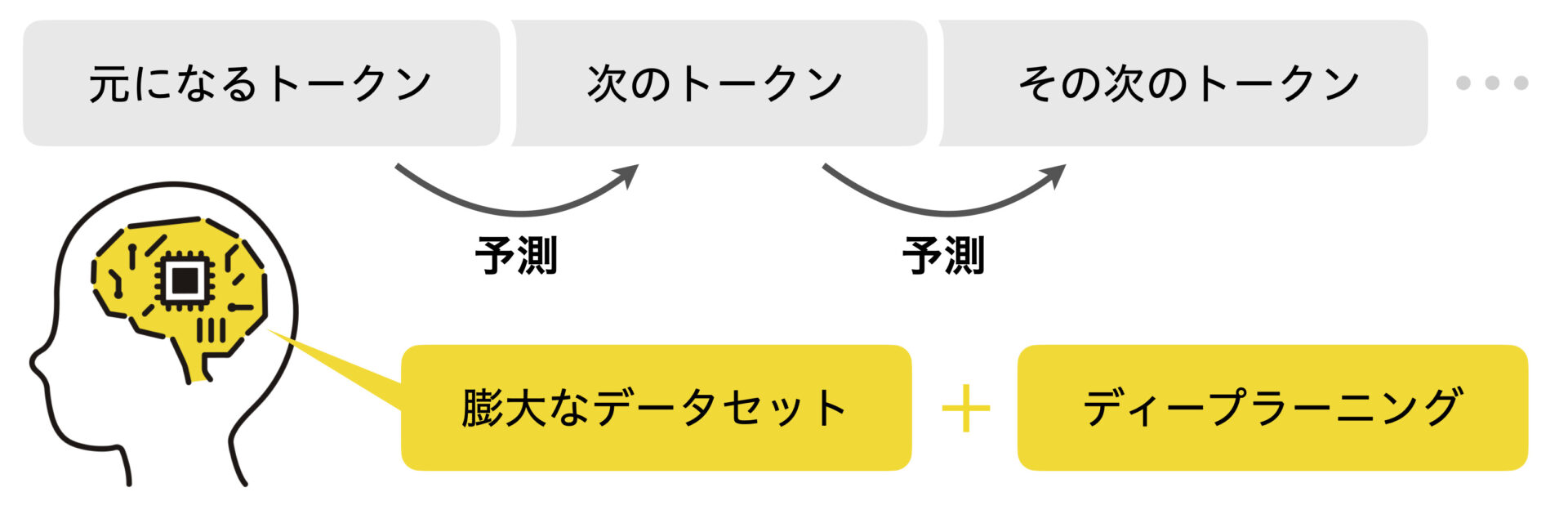
人間と “対話” するAIは、発言のその先を予測している
このように、大規模言語モデルでは、次に続くトークンを予測し、その確率を算出することで、次々と文章を生成することができます。言い換えれば、人間が入力した質問を元に、それに続く文章を生成することで、質問に対して回答することができるのです。したがって、大規模言語モデルでは、質問への回答を含めたチャットをはじめ、文書の検索や要約もできるとされています。こうした仕組みで “対話” するAIの一つが、ChatGPTです。
万能でないChatGPTとどう付き合うか
元になるデータセットが偏っていたり、最新でなかったりすることで、ChatGPTは、時に不正確・不適切な回答をすることがあります。では、そうしたChatGPTと上手く付き合うには、どのような心構えをすればいいのでしょうか。
その答えの一つは、ChatGPTに対して、完全無欠の存在であることを期待しないことです。その上で、ChatGPTに対して単に知識を問うのではなく、必要な情報をこちらから与えて情報を得る、といった使い方が適切なのかもしれません。
これからのAIとの付き合い方を考えるサイエンス・カフェが開催されます
このChatGPTをはじめとした生成系AIをテーマに扱うサイエンス・カフェが、12月3日(日)に開催されます。ゲストは、AI研究者で、北海道大学大学院 情報科学研究院 教授の川村秀憲さん。本記事で紹介したような生成系AIの仕組みを知るだけでなく、なぜ最近になって急速に発展したのか、また、こうした生成系AIを含むAIに対して、これから私たちはどのように向き合っていけば良いのかを一緒に考えます。また、サイエンス・カフェの後半では、ChatGPTもゲストに加えて、パネルディスカッションを行う予定です。
生成系AIに関心はあるけれど、まだ距離を感じている方、あるいは、もうバリバリに使っているけれど、仕事を奪われないか心配のある方、どなたでもご参加ください。お待ちしています。

【タイトル】 第133回サイエンス・カフェ札幌
「ChatGPTの先にある世界 – AIがもたらす転換期に立って」
【日 程】 2023年12月3日(日)14:30~16:00(開場 14:00)
【場 所】 紀伊國屋書店 札幌本店 インナーガーデン
(北海道札幌市中央区北5条西5-7 sapporo55 1F)
【対 象】 生成系AIに関心のある一般の方
【定 員】 40名
【参加方法】 無料、下記Webサイトより事前申込
【詳 細】 https://costep.open-ed.hokudai.ac.jp/event/28342
【主 催】 北海道大学 CoSTEP
参考文献
- Kaplan J et al. 2020: “Scaling Laws for Neural Language Models”, arXiv:2001.08361.
- 川村秀憲 2023: 『ChatGPTの先に待っている世界』dZero.
- クリフォード・A・ピックオーバー 2020: 川村秀憲(監訳) 『人工知能グラフィックヒストリー』ニュートンプレス.